How do we make Mixture-of-Experts (MoE) AI models actually fit into memory? 🧠⚡
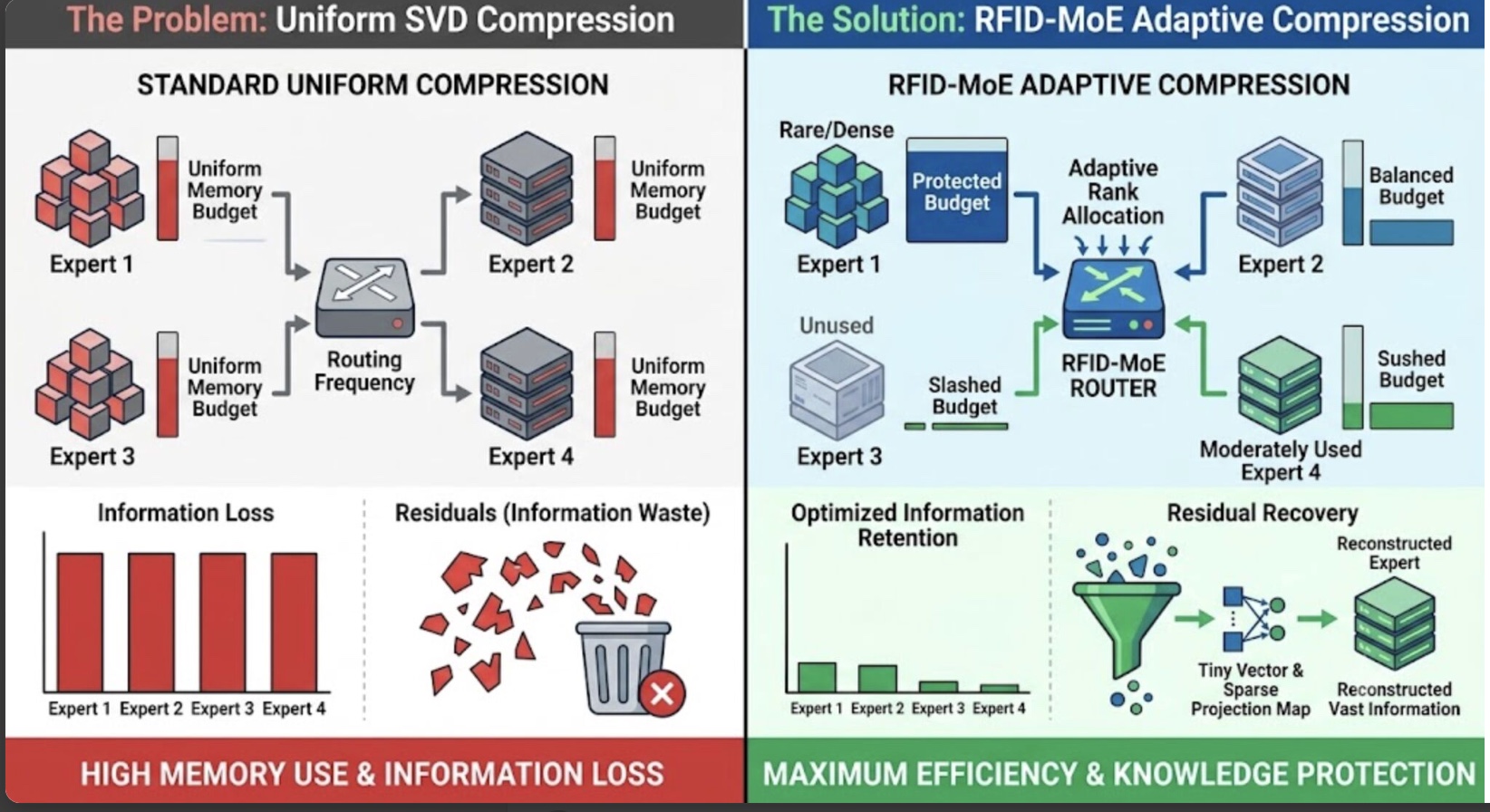
I recently dove into an incredible paper on RFID-MoE (Compression via Adaptive Routing and Information Density) , and it tackles one of the biggest bottlenecks in modern AI infrastructure: the massive memory footprint of sparsely activated models. Here is my quick breakdown of the problem and the clever engineering solutions the authors proposed: 🚨 The Bottleneck While MoE models save computing power by routing data to smaller, independent "expert" sub-networks instead of one giant network, storing all those experts still requires an immense amount of GPU memory. Standard compression techniques (like SVD) try to shrink these experts, but they suffer from two major flaws: They treat all experts equally: They ignore the fact that some experts are used thousands of times while others are rarely touched. They throw away the scraps: They treat the leftover data from compression (the "residual") as trash and discard it. 💡 The RFID-MoE Solution The authors introduced two brilliant mechanisms to optimize this workflow: 1️⃣ Adaptive Rank Allocation: Instead of a uniform memory budget, the system looks at both Routing Frequency (how often an expert is used) and Information Density (its effective rank). By fusing these two metrics, it slashes memory on unused space while fiercely protecting the highly specialized knowledge hidden in rare experts. 2️⃣ Parameter-Efficient Residual Reconstruction: Instead of throwing away the compression leftovers, they recycled them! They captured the residual into a tiny, low-dimensional vector and used a clever sparse projection matrix to map it back into the model. The result? They recovered a massive amount of lost information with almost zero extra memory footprint. The Takeaway: Great AI engineering isn't just about building bigger models; it's about finding elegant, hardware-efficient ways to serve them.
Traditionally, standard Large Language Models (LLMs) process a tokenized sentence by passing every single piece of data through one giant, dense neural network.
To bypass the massive computational bottleneck of this approach, modern AI relies on an existing architecture called Mixture-of-Experts (MoE). In an MoE model, that giant network is replaced by independent sub-networks called "experts," alongside a "router" module that decides which specific experts are the most relevant for each token.
While MoE models save computing power by only activating a few experts at a time, storing all of these experts requires a massive amount of memory. To alleviate this, current solutions use a compression technique called Singular Value Decomposition (SVD), which shrinks the experts by finding simpler, low-rank mathematical approximations of their data
However, the authors of the RFID-MoE paper correctly identified two major flaws in how SVD is currently used:
- Treating all experts equally: SVD methods usually assign a uniform memory budget to all experts. This ignores the highly imbalanced usage of experts—some are routed to thousands of times, while others are rarely used.
- Throwing away the scraps: When SVD compresses data, some information is inherently lost. This leftover data is called the "residual." Older SVD methods assume this residual is negligible and simply throw it away
The Solution: RFID-MoE
To address these two disadvantages, the authors designed the RFID-MoE framework, which introduces two clever mechanisms:
1. Adaptive Rank Allocation Instead of treating all experts equally, the authors designed a system that gives a larger memory budget to the most important experts and a smaller budget to the least important ones. Here is how that budget is decided:
- The system evaluates both the Routing Frequency (how often an expert is used) and the Information Density of the experts.
- To figure out the information density, the authors measure an expert's effective rank.
- By fusing Routing Frequency and Information Density, the model perfectly balances saving memory on unused space while protecting the highly specialized knowledge hidden inside rarely used experts.
Parameter-Efficient Residual Reconstruction When applying SVD compression, we naturally get some residual leftovers. Instead of throwing them away, the authors designed a mechanism to recycle them.
- The residual is captured into a tiny, low-dimensional mathematical vector.
- Then, they use a clever sparse projection matrix to map this tiny vector back into the larger model.
- This allows the system to recover a massive amount of lost information with almost zero extra parameters added to the model’s overall memory footprint.
A Closer Look: How the MoE Routing Algorithm Works
To understand how the router assigns data to the experts, we can look at the elegant equation that governs it: G(x)=TopK(Softmax(Wgx))
Here is the step-by-step breakdown of how a token is routed:
- The Setup: When a token enters the MoE layer, it is represented as a mathematical vector (x). The router itself is a mini neural network containing a learnable parameter matrix. This matrix acts as a rubric that the router has learned over time to understand which of the n independent experts is best suited for different mathematical patterns.
- The Comparison(Wgx): The first step is to mathematically multiply the incoming token vector by the router's parameter matrix. The outcome of this multiplication acts as a massive comparison operation, calculating a raw affinity score for every single expert in that specific layer.
- Converting to Probabilities (Softmax): Those raw scores are then passed into the Softmax function, which transforms them into a clean probability distribution. For example, the output might look like:
- Expert 1 (Grammar): 85%
- Expert 2 (Math): 2%
- Expert 3 (Science): 1%
Making the Choice (TopK): Finally, the router uses the Top-K function to pick the experts with the highest probabilities, sending the token only to the top 1 or 2 winners to be processed
Reference
Mi, Z., Chen, Y., Zhao, P., Yu, X., Wang, H., Wang, Y., & Huang, S. (2026). Effective MoE-based LLM Compression by Exploiting Heterogeneous Inter-Group Experts Routing Frequency and Information Density. arXiv preprint arXiv:2602.09316.