Tyche: Optimizing Serverless Machine Learning via Proactive Pre-Loading
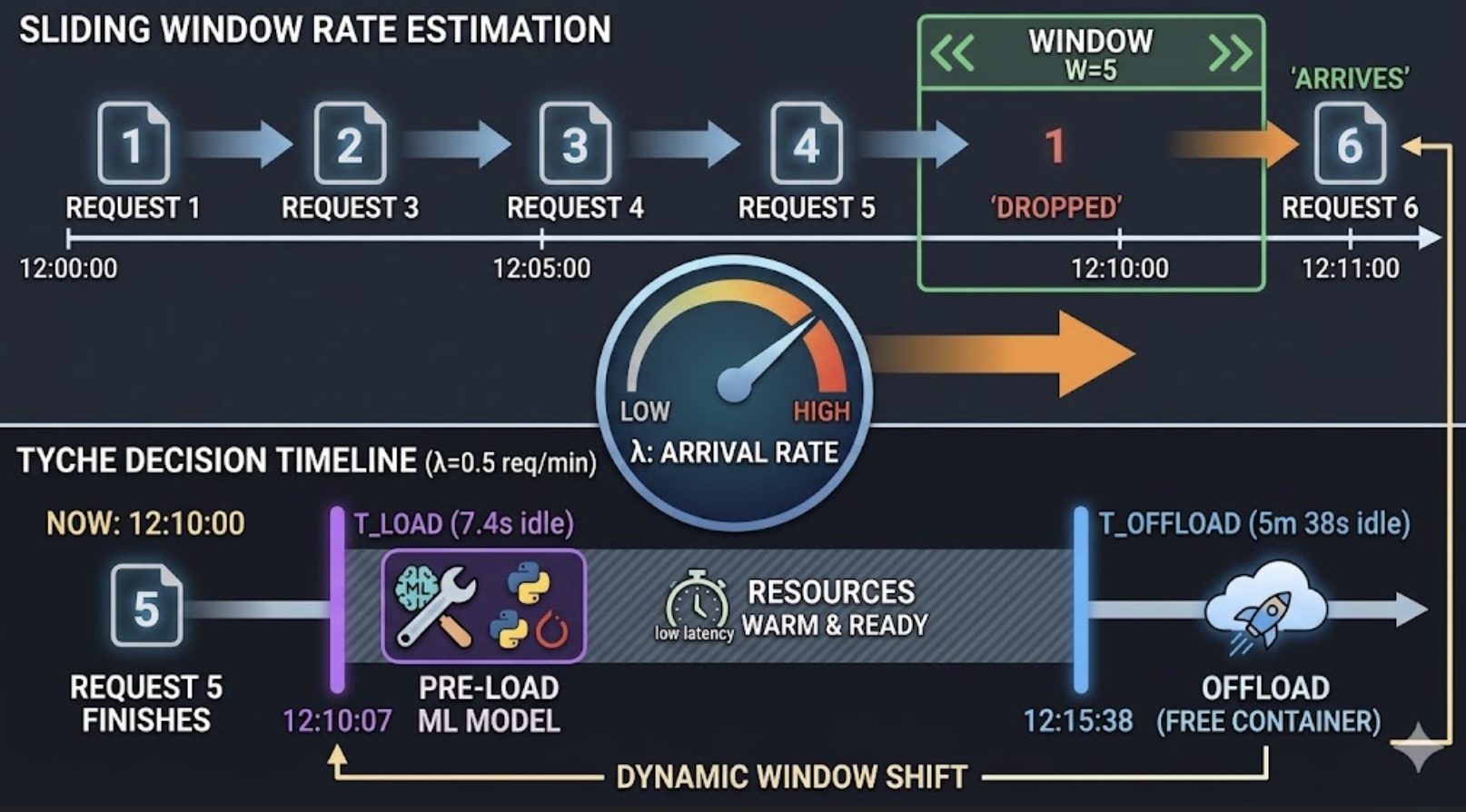
Can we completely eliminate Machine Learning "Cold Starts" in Serverless Clusters? When packaging ML models into serverless functions, the standard "container pre-warming" used by cloud providers isn't enough. Why? Because traditional apps are lightweight, but ML workflows carry massive dependencies (like PyTorch) and heavy model files (like BERT). A staggering 70% of a serverless ML cold start is spent just loading these libraries from disk into memory. In my latest technical report, I break down "Accelerating ML Inference via Opportunistic Pre-Loading on Serverless Clusters" (published in IEEE Transactions on Parallel and Distributed Systems*, Vol. 37, No. 2, February 2026). The paper introduces Tyche, an architecture that solves this by opportunistically pre-loading ML artifacts into already-warmed containers and GPUs before a request even lands. Here is how the underlying math dynamically handles erratic traffic spikes without wasting heavy CPU retraining cycles: ⏱️ The 7.4-Second Math Adaptation Instead of relying on rigid, historical 24-hour traffic averages that fail during sudden surges, Tyche monitors a tight sliding window of recent requests (e.g., W=5) to calculate the request arrival rate (lambda). It then plugs this live rate into a Poisson distribution formula using two optimal probability thresholds: Load Threshold P_load = 6 The moment the probability of an incoming request hits 6%, Tyche acts. For a standard traffic pace of 0.5 requests/min, the math triggers a proactive pre-load timer at exactly 7.4 seconds of idle time. The model is booted and waiting before the user arrives. Offload Threshold P_offload = 94%: If a traffic lull happens and the probability that a prediction was wrong hits 94% (around 5.6 minutes), Tyche immediately flushes the model to keep the cluster memory lean. ⚡ The Real Engineering Win When a sudden burst of traffic hits, the sliding window instantly recalculates. If $\lambda$ jumps from 0.5 to 0.55: 1. Zero Retraining Overhead: No heavy GPU/CPU cycles are wasted adjusting complex ML weights. 2. Instant Math Recalculation: The target pre-load window automatically tightens from 7.4 seconds down to ~6.7 seconds. The entire system winds up aggressively during surges and relaxes during lulls—yielding up to a 93% reduction in loading latency. #Serverless #MachineLearning #SystemArchitecture #CloudComputing #AWSLambda #DistributedSystems #IEEE #TechCommunity