Tyche: Optimizing Serverless Machine Learning via Proactive Pre-Loading
Can we completely eliminate Machine Learning "Cold Starts" in Serverless Clusters? When packaging ML models into serverless functions, the standard "container pre-warming" used by cloud providers isn't enough. Why? Because traditional apps are lightweight, but ML workflows carry massive dependencies (like PyTorch) and heavy model files (like BERT). A staggering 70% of a serverless ML cold start is spent just loading these libraries from disk into memory. In my latest technical report, I break down "Accelerating ML Inference via Opportunistic Pre-Loading on Serverless Clusters" (published in IEEE Transactions on Parallel and Distributed Systems*, Vol. 37, No. 2, February 2026). The paper introduces Tyche, an architecture that solves this by opportunistically pre-loading ML artifacts into already-warmed containers and GPUs before a request even lands. Here is how the underlying math dynamically handles erratic traffic spikes without wasting heavy CPU retraining cycles: ⏱️ The 7.4-Second Math Adaptation Instead of relying on rigid, historical 24-hour traffic averages that fail during sudden surges, Tyche monitors a tight sliding window of recent requests (e.g., W=5) to calculate the request arrival rate (lambda). It then plugs this live rate into a Poisson distribution formula using two optimal probability thresholds: Load Threshold P_load = 6 The moment the probability of an incoming request hits 6%, Tyche acts. For a standard traffic pace of 0.5 requests/min, the math triggers a proactive pre-load timer at exactly 7.4 seconds of idle time. The model is booted and waiting before the user arrives. Offload Threshold P_offload = 94%: If a traffic lull happens and the probability that a prediction was wrong hits 94% (around 5.6 minutes), Tyche immediately flushes the model to keep the cluster memory lean. ⚡ The Real Engineering Win When a sudden burst of traffic hits, the sliding window instantly recalculates. If $\lambda$ jumps from 0.5 to 0.55: 1. Zero Retraining Overhead: No heavy GPU/CPU cycles are wasted adjusting complex ML weights. 2. Instant Math Recalculation: The target pre-load window automatically tightens from 7.4 seconds down to ~6.7 seconds. The entire system winds up aggressively during surges and relaxes during lulls—yielding up to a 93% reduction in loading latency. #Serverless #MachineLearning #SystemArchitecture #CloudComputing #AWSLambda #DistributedSystems #IEEE #TechCommunity
Tyche is an innovative solution designed to solve the problem of latency, particularly when it comes to serverless platforms that run machine learning (ML) inferences. When we package ML inferences into a container, there are a few steps involved, including container initialization, setting up the network, and configuring the runtime environment.
For regular applications, these initialization steps take the majority of the latency time to execute. However, with ML models, we often deal with very heavy dependencies—such as PyTorch—or need to deserialize massive model files like BERT. Because of this, a staggering 70% of the overall time is devoted purely to the loading phase of these libraries. Tyche solves this problem by opportunistically pre-loading the ML artifacts into containers and GPUs in advance, specifically targeting already-warmed containers.
The Proactive Pre-Loader and the Sliding Window One of the most interesting features of Tyche is the Proactive Pre-Loader, which forecasts when an invocation will arrive. To forecast these invocations, Tyche relies on the serverless platform's existing prediction models, utilizing techniques such as the Histogram Policy, ARIMA, Random Forest, or Poisson Distributions.
Because invocation patterns do not stay the same and constantly shift, Tyche addresses this by leveraging a sliding window technique. This approach dynamically adjusts to capture each function's temporal shifts, ensuring that the prediction model only uses the most recent and relevant data without needing to alter the underlying prediction algorithm itself.
Load and Offload Thresholds In the context of the Tyche system, there are two critical probability thresholds that must be cleared: load and offload. These refer to the specific actions taken by the Proactive Pre-Loader to manage when machine learning artifacts (like models and libraries) are placed into or removed from an idle container's memory.
- Load (P_load = 0.06): The optimal probability threshold for pre-load is 0.06 (6%). This means if the forecasted probability of an invocation hits 6% or more, the artifacts get loaded.
- Offload (P_offload = 0.94): The optimal probability threshold for offloading is 0.94 (94%). When the probability hits this mark, it means the prediction was likely incorrect, and the artifacts can be offloaded to free up space.
These numbers are then plugged into a Poisson distribution formula to calculate the exact estimated pre-loading time and offloading time.
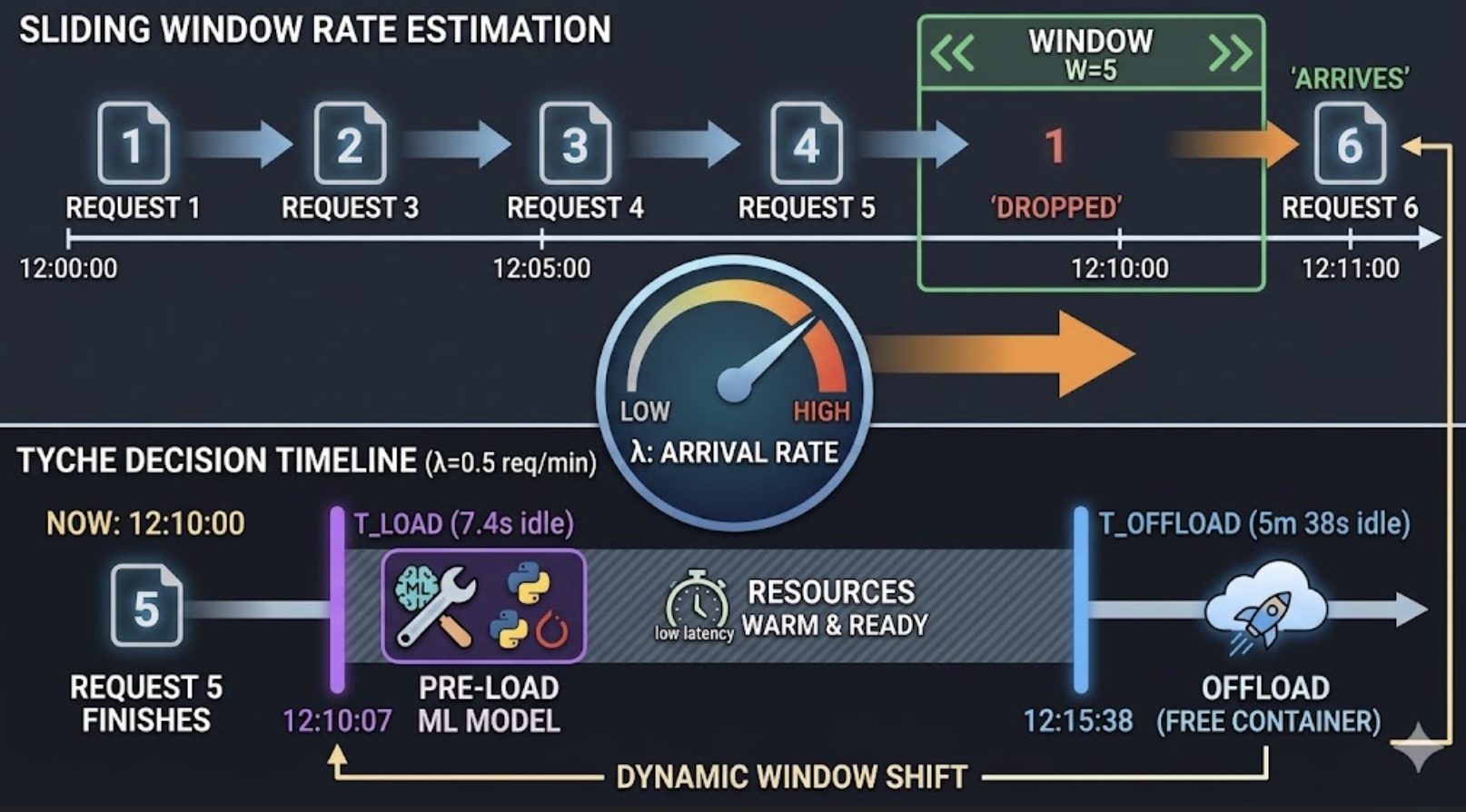
How It Works in Practice: A Step-by-Step Example To better understand how Tyche uses this technique, imagine you have a specific serverless ML function (like an image classifier). Tyche tracks its most recent invocations using a sliding window. For this example, let's set the window size (W) to 5 invocations.
Assume the last 5 invocations arrived at the following timestamps:
- Request 1: 12:00:00
- Request 2: 12:02:00
- Request 3: 12:05:00
- Request 4: 12:07:00
- Request 5: 12:10:00 (This is "now")
Step 1: Calculate the Request Arrival Rate (λ) First, Tyche calculates the duration (T) between the first and last invocations inside the window.
- 12:10 - 12:00 = 10 minutes.
- The arrival rate (λ) is the window size divided by the duration: 5 / 10 = 0.5.
Step 2: Apply the Probability Thresholds Tyche uses its fixed probability thresholds to decide exactly when to act. Based on sensitivity analysis, the optimal defaults are applied:
- Pload=6% (0.06)
- Poffload=94% (0.94)
By plugging these thresholds and the arrival rate of 0.5 into the Poisson distribution formula, Tyche can accurately calculate the optimal future timestamps to either load the model in preparation for the next user or clear it out of memory.
Step 3: Apply the Poisson Distribution Formulas Tyche plugs the arrival rate (λ=0.5) and thresholds into the Poisson distribution formulas to calculate the exact future timestamps for loading (T_load) and offloading (T_offload):
- Pre-loading Formula: Tload=−1/λ * ln(1−P_load)
- Calculation: T_load=−(1/0.5)∗ln(1−0.06)
- Result: ~0.124 minutes (about 7.4 seconds)
- Offloading Formula: Toffload=−1/λ* ln(1−P_offload)
- Calculation: T_offload=−(1/0.5)∗ln(1−0.94)
- Result: ~5.626 minutes (about 5 minutes and 38 seconds)
The Resulting Action Right after the 5th request finishes at 12:10:00, Tyche starts a timer.
- If the next request hasn't arrived within ~7.4 seconds, Tyche proactively triggers the load command at 12:10:07 to ensure the model is waiting in memory.
- If the function continues to sit idle in memory and a new request still hasn't arrived by 12:15:38, Tyche assumes its prediction was wrong and immediately offloads the model to free up container space.
Why the Sliding Window is the Real Hero
Consider what happens when a sudden burst of traffic hits the system, starting with a rapid "Request 6." Traditional serverless management relies on static, historical averages (like looking at the last 24 hours of traffic). Under a static model, a sudden noon spike wouldn't register quickly enough, resulting in severe latency spikes and cold starts for your users.
By utilizing a dynamic sliding window size of W=5, Tyche completely bypasses this limitation with two major engineering advantages:
- Zero Retraining Overhead: The system avoids wasting heavy CPU or compute cycles recalculating complex machine learning weights every time a traffic shift occurs.
- Instant Mathematical Adaptation: Tyche dynamically updates the arrival rate lambda from 0.5 to 0.55. Re-applying lambda = 0.55 into our Poisson equations immediately drops T_load to ~6.7 seconds and shortens T_offload to ~5.1 minutes.
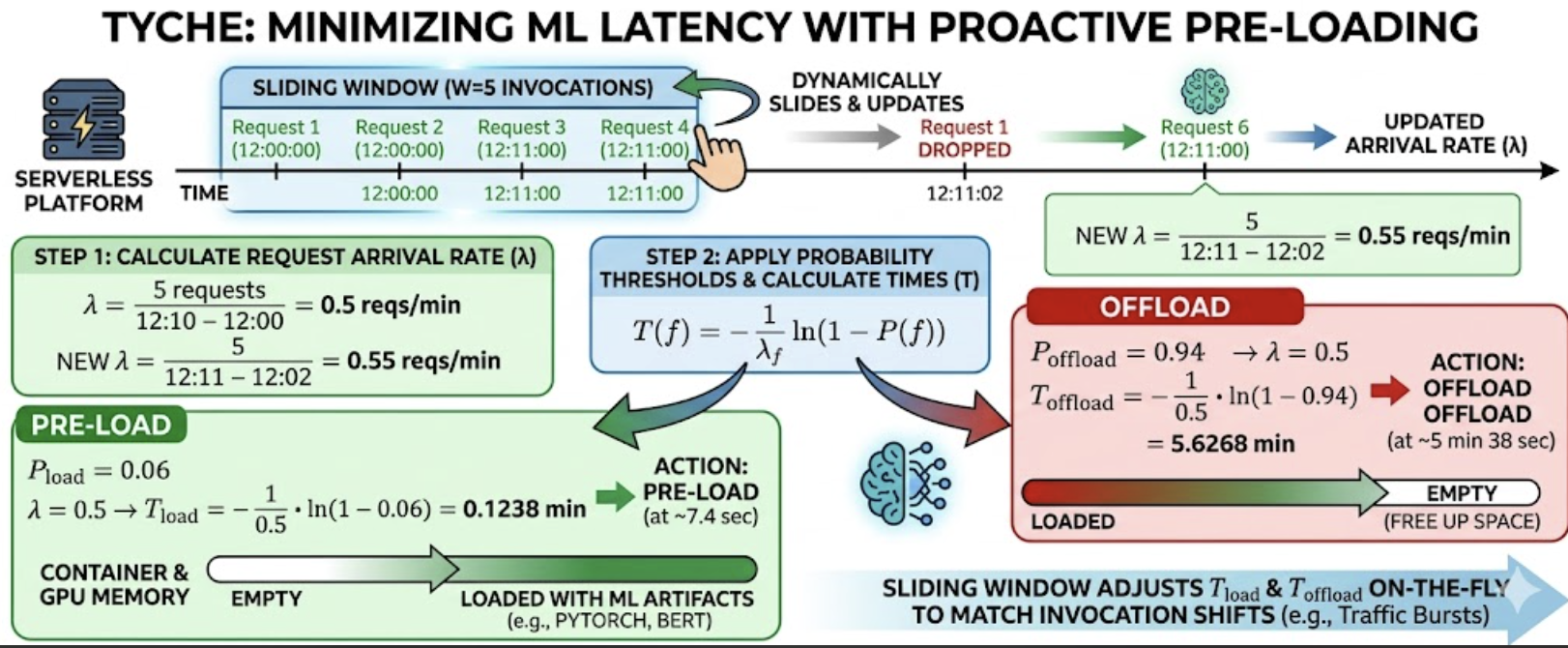
Ultimately, the architecture automatically tightens its operations and becomes more aggressive during high-traffic surges, gracefully relaxing during seasonal lulls.
Reference:
Y. Sui, H. Yu, Y. Hu, J. Li and H. Wang, "Accelerating ML Inference via Opportunistic Pre-Loading on Serverless Clusters," in IEEE Transactions on Parallel and Distributed Systems, vol. 37, no. 2, pp. 472-488, Feb. 2026, doi: 10.1109/TPDS.2025.3638428. keywords: {Containers;Loading;Load modeling;Graphics processing units;Libraries;Job shop scheduling;Costs;Machine learning;Serverless computing;Runtime environment;Serverless computing;cloud computing;cold start;machine learning},